You have /5 articles left.
Sign up for a free account or log in.

Bortonia/iStock/Getty Images Plus
Yet another study is challenging the idea that student evaluations of teaching reliably measure what they’re intended to measure: instructional quality.
The new study, available now as a preprint, builds on the well-documented correlation between students’ grades and how they rate teachers (i.e., students who earned better grades in a course tend to rate those instructors more highly than peers who got lower grades). After testing and eliminating other possible drivers of this correlation, the study ultimately asserts that it’s not about instructional quality, workload or grading stringency or leniency.
Instead, the paper says, student grade satisfaction drives this correlation.
The authors of the paper also tested out an intervention that held some promise in another research setting: reminding students what course evaluations are really about, and the stakes of these ratings for professors. But even these steps didn’t consistently make a difference in the new study.
Like other studies before it, the paper poses urgent questions about how institutions should use student evaluations of teaching, if at all. Numerous colleges and universities have moved away from considering them in high-stakes personnel decisions in recent years, but they’re still widely used for this purpose on many campuses.
Adjunct faculty members, who often work at the fringes of their departments, are especially likely to be reappointed—or not—based on student ratings, posing potential pedagogical and ethical problems. Most significantly, there is a risk that these professors may feel pressured into awarding higher grades in order to be rated more highly by students, all to remain employed.
Vladimir Kogan, associate professor of political science at Ohio State University and a co-author on the new study, said, “The burden of proof is really on the wrong side right now. Proponents of SET [student evaluations of teaching] should show that they actually improve student outcomes—achievement, persistence, completion, et cetera. The best prior evidence that has been presented—that SET are positively correlated with student grades—clearly do not establish that, as our study shows once again.”
Kogan remains “open to the possibility” that such evidence of these could be found, “or that a world with SET, with their flaws and all, might be better than a world without them. But again, we should expect to see evidence of this rather than assuming that this is the case.”
Educators have over the years toyed with the idea of somehow adjusting student ratings for grades given, to mitigate the known grade-rating effect. One concern—including at Ohio State, Kogan said—has been that professors may start to grade students lower to get a larger statistical correction.
Institutions have been less concerned about the “status quo” having the opposite effect: professors grading students higher to get higher ratings, Kogan said. “It’s not clear why folks were so worried about one—worried enough to reject statistical correction—but not about the other.”
Some proponents of student evaluations have mused that better grades simply reflect better teaching. But several peer-reviewed studies have discredited that idea.
Crucially, Kogan’s study also rules out the notion that students simply reward easier classes with better ratings for the instructor, as the analysis takes students' class sections, and therefore what it calls "class fixed effects," into account.
What the Study Did
For their study, Kogan and his co-authors considered 19,158 spring 2021 course evaluations completed by 14,051 students in 718 classes in either the College of Arts and Sciences or the College of Food, Agricultural and Environmental Sciences at Ohio State. They also gathered each student’s final course grades and major.
Compared to students who got an A, students who got an A-minus rated the class 0.22 points lower over all, on average, on a five-point scale used by Ohio State. Students who got a B rated the class 0.34 points lower. Scores fell further for lower passing grades, to about 0.5 points lower than reported by A students. Students who failed rated their course more than 0.7 points lower than A students.
In addition to being highly statistically significant, these differences are large, the paper says: “Average scores on the overall satisfaction survey question typically have a class-level standard deviation between 0.9 and 1. The difference in average evaluation scores given by students who receive an A and an A-, representing a modest grade difference, ranges from 0.1 to 0.2, depending on the specification, corresponding to between 10 percent and 20 percent of a standard deviation.”
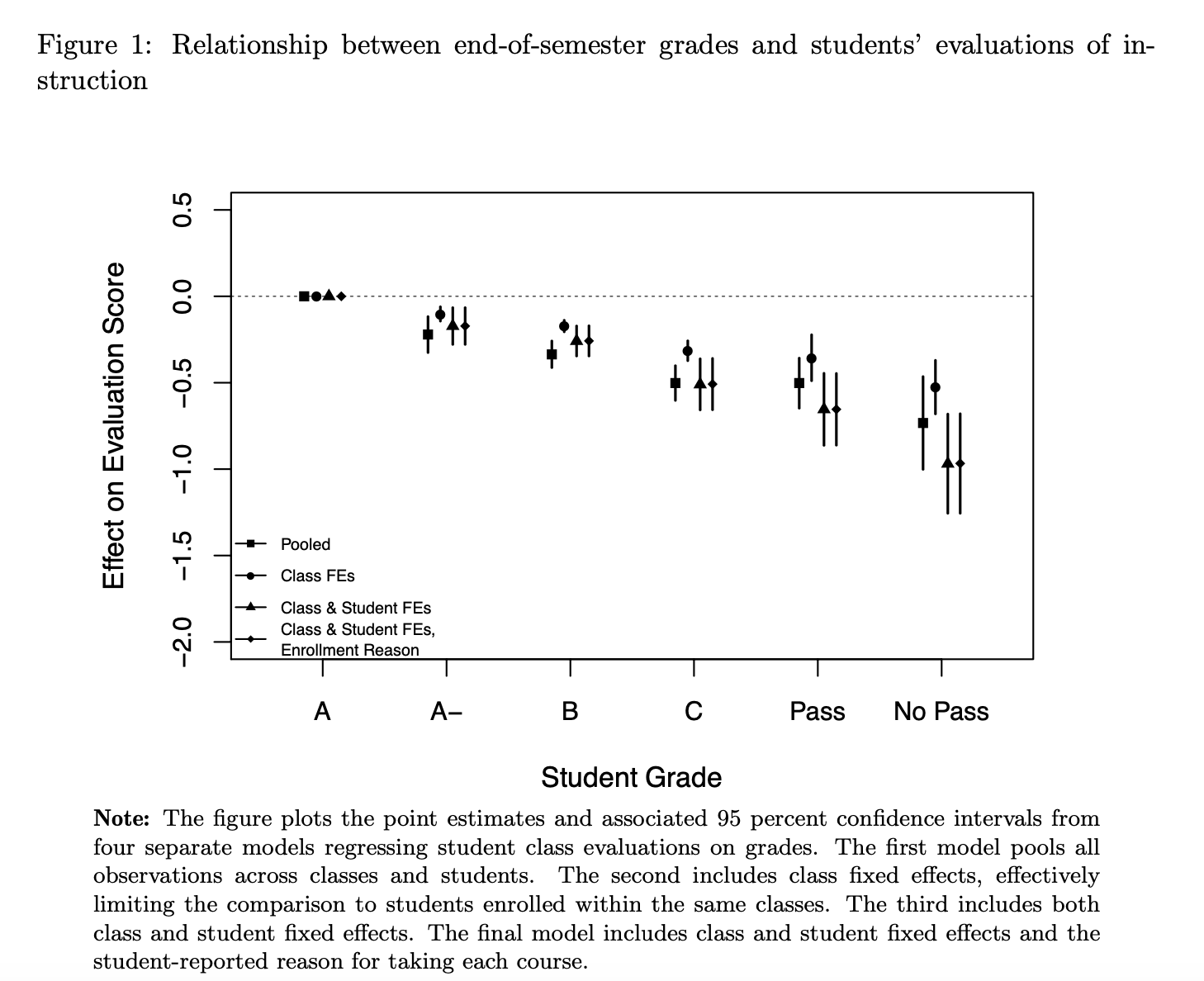 Because the analysis controlled for students' sections sections, this difference could not be explained by either workload, grading leniency or quality of instruction, which are essentially the same within sections. Nor could it be explained by intrinsic differences among students, including students' self-reported reasons for taking a given course, the study says (this student-centric part of the analysis involved data from students who took multiple classes that were part of the study).
Because the analysis controlled for students' sections sections, this difference could not be explained by either workload, grading leniency or quality of instruction, which are essentially the same within sections. Nor could it be explained by intrinsic differences among students, including students' self-reported reasons for taking a given course, the study says (this student-centric part of the analysis involved data from students who took multiple classes that were part of the study).
In other words, the study says, “students who receive better grades tend to report a subjectively more positive experience in their courses, regardless of the underlying reasons that led to their high performance.”
Kogan and his team also tested an intervention—including one, both or neither of the following statements on the student survey instrument—to see how reminding them of the survey’s purpose and significance might affect their ratings:
1) The Ohio State University recognizes that student evaluations of teaching are often influenced by students’ unconscious and unintentional biases about the race and gender of the instructor. Women and instructors of color are systematically rated lower in their teaching evaluations than white men, even when there are no actual differences in the instruction or in what students have learned. As you fill out the course evaluation, please keep this in mind and make an effort to resist stereotypes about professors. Focus on your opinions about the content of the course (the assignments, the textbook, the in-class material) and not unrelated matters (the instructor’s appearance).
2) Student evaluations of teaching play an important role in the review of faculty. Your participation in this process is essential; having feedback from as many students as possible provides a more comprehensive view of the strengths and weaknesses of each course offering, allowing instructors to improve their practices and increase learning. Moreover, your opinions influence the review of instructors that takes place every year and will be taken into consideration for decisions regarding promotion and tenure.
The interventions had some apparent effect, in some cases. For example, students who earned an A-minus rated their course significantly more positively when provided the high-stakes introductory language compared to students completing the standard (no intervention) survey. Yet there was no consistent positive effect across students: those who got a B, for instance, rated their course significantly more negatively—yes, negatively—when provided the implicit bias text.
The authors caution that their results should not be read to imply that student grades are the only—or even most important—predictor of student course evaluations, as grades explain less than 5 percent of the variation in student evaluation scores in their data. It’s possible that instructional quality does factor in, but that’s not sufficiently clear, they say.
At minimum, the study says, “our results suggest that supporters of student evaluations should face the burden of proof to show that evaluations measure and incentivize desirable teaching practices that promote students’ long-term success.”
The second part of Kogan’s working paper, which has already been published in its own right in Applied Economic Perspectives and Policy, was inspired by a separate 2019 study that found relatively simple changes to the language used in SETs can make a positive impact in assessments of female professors, reducing the well-documented problem of gender bias in evaluations. Yet even at the time, the authors of that other paper warned that if their intervention was widely adopted, the positive effect for female professors could wear off as students adjusted and transferred their biases to the new system.
David A. M. Peterson, Lucken Professor of Political Science at Iowa State University, co-wrote the 2019 paper that inspired the intervention piece of Kogan’s study, and he said that both of Kogan’s analyses are “remarkably well done.”
The data that Kogan and his colleagues were able to access are “substantially better than ours,” in terms of sample size and more, he added. “It really makes me think that our results were outliers and do not replicate.”
Peterson also said he agreed with the “general conclusion that we won’t be able to tweak our way out of these issues. There are fundamental issues in SETs that universities are delinquent if they don’t address.” If a university “wants to take teaching and the evaluation of teaching seriously,” he continued, it needs a “more holistic and less biased set of metrics for evaluating faculty.”





